the key idea about transformers was the self-potential mechanism uh that was developed in 2017
GPT intro
GPT 的全名就是 generative pre-trained transformer
预训练是指模型如何从大量数据中学习的过程,前缀 Pre 暗示有更多空间通过额外的训练来针对特定任务对其进行微调。
The last piece that’s the real key, a transformer is a specific kind of neural network, a machine learning model, and it’s the core invention underlying current boom in AI
你可以用就是 transformer 创造很多类型的模型,比如说 voice to text what text to voice, text to image These are based on transformer
之所以可以用 transformer 这种预测模型来生成一段新文本是因为你可以给他一个文本片段,然后他 predict 下一个单词,组成一个新的片段。然后你再把这个新的片段又丢进去,去 predict 下一个单词就这样
基本就是这样 一段文本进入Transformer 得到一个词的distribution of probabilities
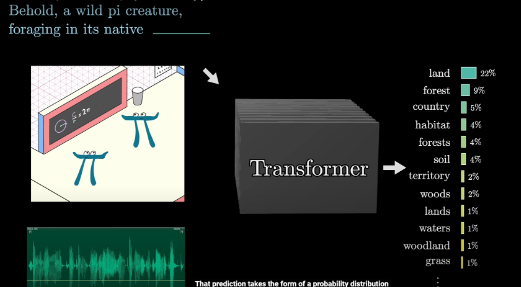
How Data flows in Transformer (Generally)
flowchart TD
subgraph Input["输入层 (Raw Tokens)"]
A[("Token 序列")]
end
subgraph Embedding["Embedding层"]
B1["Embeddings Matrix查找"]
B2["向量映射 (12800维)"]
end
subgraph TransformerFlow["Transformer核心"]
subgraph AttentionBlock["Attention Block"]
D1["多头注意力机制"] --> D2["残差连接"]
D2 --> D3["层归一化"]
D3 --> D4["MLP"]
D4 --> D5["残差连接"]
D5 --> D6["层归一化"]
end
C["向量序列"] --> D1
D6 --> E["下一个Attention Block"]
end
subgraph Output["输出层处理"]
F1["Unembedding Matrix"]
F2["50000维词表映射"]
G1["Softmax温度调节"]
G2["概率分布输出"]
end
A --> B1
B1 --> B2
B2 --> C
E --> F1
F1 --> F2
F2 --> G1
G1 --> G2
%% 添加说明注释
classDef process fill:#f9f,stroke:#333,stroke-width:2px
class D1,D4 process
%% 添加关键步骤说明
note1[/"输入token转换为向量"/]
note2[/"上下文信息交互"/]
note3[/"生成预测概率"/]
B2 -.-> note1
D1 -.-> note2
G2 -.-> note3
tokens

视频,音频,文本的”a piece”都可以是 token
A token doesn’t align with a word
 the first time I met token
the first time I met token
每一个 token 都对应一个 vector, 这也就是这一串数字的目的,是以某种方式来表达这一个 token 的含义
this vector somehow encode the information a token contain
if you think of these vectors as giving coordinates in some very high dimensional space.You will find words with similar meaning tend to land on vectors that close to each other in that space 向量
也就是说每一个 token 在 high dimensional space 都可以表现为一个 informational 的向量 相同意思的token的坐标应该相近
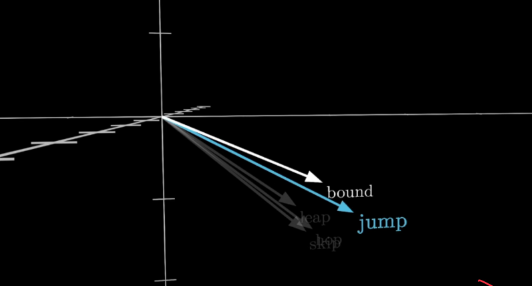
这可以看成一个三维空间的切片
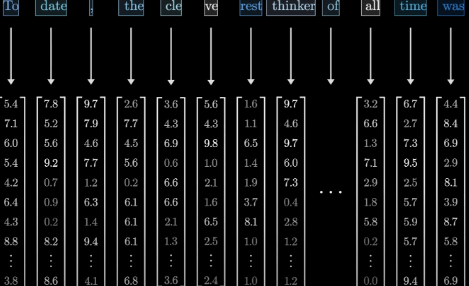
Transformer 的 tokens 应该要转化成 vectors,一个 token 对应一个 vector 从 embeddings matrix 里取出对应 token 的向量 vector,就完成了 tokens->vectors,我们可以想象当 input data 在 Transformer 中流动的时候 他就长这样一个 vectors 构成的 sequence 的样子
1 | # 假设的伪代码 |
然后刚刚生成的这一个 token 的序列,这一堆 vectors 会经过一个过程,叫做注意力块的处理过程。
Attention Block
WHY need attention block.
A token is not supposed to be just the exact original meaning(in embeddings matrix) 比如 model 这个词,我们假设他是一个 token,machine learning model 和 fashion model 的意思肯定不一样,但他们的 Pre-trained embeddings matrix 里的向量是一样,但模型应该知道他们的意思不一样,也就是说模型应该学习到这个意义
The vector in embeddings matrix encoded the original information which should change into the meaning it is supposed to be in THE CONTEXT
在 attention block 这些 Vector 会互相作用
接着刚刚说的我们现在有 vectors 的序列,这个序列在这个注意力块里,这些向量能够相互交流,他们可以 pass information back and forth
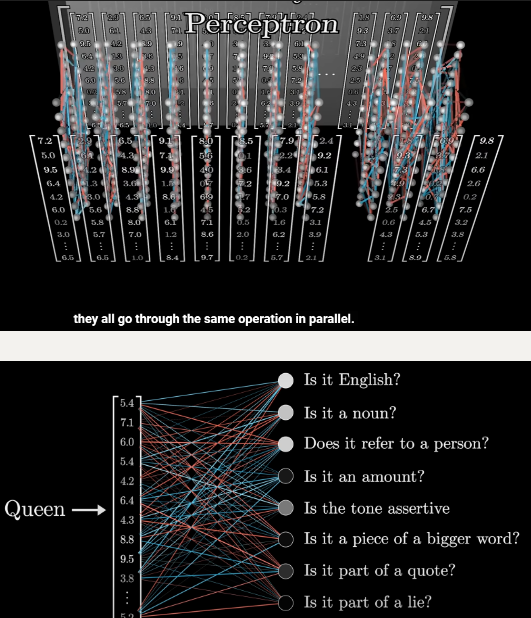
Multilayer Perceptron
多层感知机
简单来说:对每个向量提出一系列的问题, 然后根据这些问题的答案来更新向量
这样重复这两个过程
Final Processing vectors
Dive into
Premise:What is Weight
To simplify:the model’s weights (numbers that control the prediction)
We start with the simplest machine-learning model: linear model
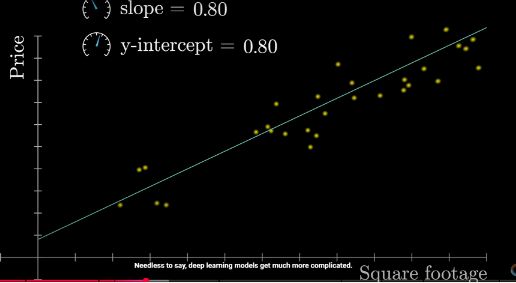
数学表达式 y = wx + b
- y: 预测值
- x: 输入特征
- w: 权重(weight)
- b: 偏置(bias)
We see x as a vector and by processing(computing) x with weight and bias,in the high semantic dimensional space we have changed the meaning x originally represents.
About Input tokens
Input is just what the model processes,the actual brain of Transformer is WEIGHTS.
模型拥有一个预设的词汇库,包含所有可能的单词, 比如说有 50,000 个
这个词汇表以 Embedding matrix 的形式存储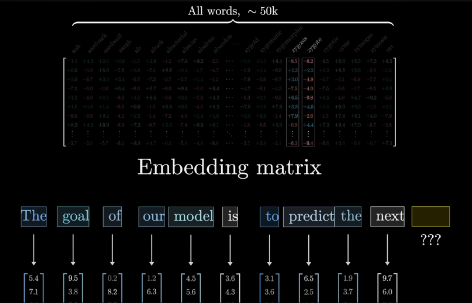
this is pre-trained which somehow encoded the information a single token should represent!
Which is to say : these columns are what determines what vector each word(token) turns into IN THE FIRST STEP
And 不管你构建的是哪种模型,输入都必须是一个实数数组这可能只是一个数字列表,也可能是一个二维数组,或者更常见的是更高维度的数组,通用的术语我们称之为张量
So ⬇️
How many dimensions can x be
As we already know:In the perception of Transformer,Input data is sequence of vectors (high dimensional vector)
So how many numbers are in a vector ?🤨
take GPT-3 for example :12800 dimension,which means 12800 rows for a vector
review key concept
这里的关键思想是,模型在训练过程中调整和微调权重, 以确定词具体如何被嵌入为 final 向量
how exactly words get embedded as vectors during training
What happens in the Attention block and 多层感知机
we’ve said that “这里的关键思想是,模型在训练过程中调整和微调权重”
So In the Attention block that’s what happened.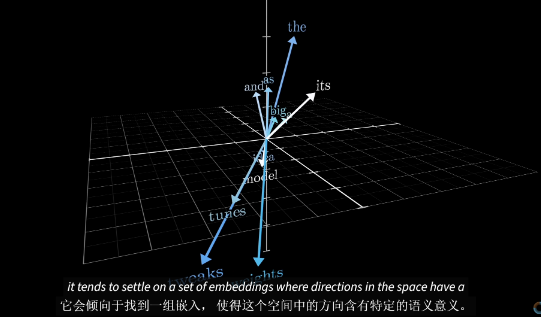
And it does that by what we have mentioned:Weights
1 | Attention block核心过程 |
每个 vector 都会:
- 与其他 vectors 交互
- 交换信息
- 根据交互结果调整自身表征
In GPT-3

these weights constantly changed during the process of training
How do we get weights
预测阶段(Inference)
- 改变的是:input vectors matrix
- 动态调整 tokens 之间的关系
- 不改变模型权重
训练阶段(Training)
- 改变的是:模型的 weights
- 通过反向传播
- 目的:学习如何更好地捕捉 tokens 间关系
所以我们通过学习得到一个 reasonable weights
WHY do they (weights) change
The ULTIMATE Goal 是最小化整体预测误差
1 | 输入x → 模型预测 → 计算误差 → 调整weights |
How they change
- 损失函数(Loss Function)衡量预测误差
- 梯度下降法计算权重调整方向
- 通过反向传播(Backpropagation)更新权重
The most popular algorithm today’s models are mostly using
The model is given an input vector, makes a prediction, compares that prediction to the expected output, and then uses the error (quantified by the loss function) and the gradient of that error to adjust its weights.
This adjustment process is what we call “learning.”
The results of learning ,of adjusting weights
假设你不知道表示“女性君主”的词 你可以通过向“国王”向量添加“女人减男人”的方向 并搜索最接近这个点的词向量来找到它。
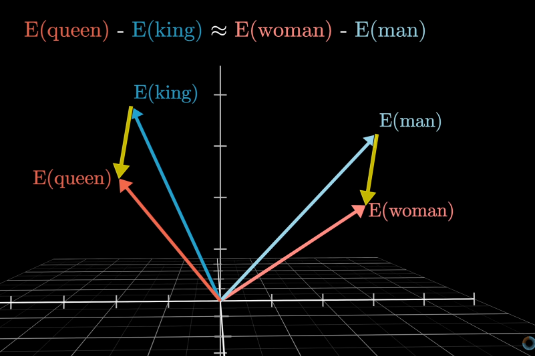
关键在于,在训练过程中, 模型发现采用这样的嵌入方式更为有利 即他学会了这个空间中的一个方向能够编码性别信息
And it has found a proper vector to encode the information the token represents! Not just its original meaning,But IN THE CONTEXT
In this step,What does a well-trained vector mean
we have got processed vectors by filtering with weights
Which means What we are asking right now is (In Y=WX+B)
What does WX mean now
It means it’s context-encoded

Let’s summarize it:
一个词的意义很大程度上是由其所处的环境决定的 有时这甚至包括来自很远的上下文。 因此,在构建一个能预测下一个词汇的模型时 关键目标就是让它能够高效地融合上下文信息。当我们根据输入文本创建向量数组时, 每个向量都是直接从嵌入矩阵中选取的。这意味着,起初,每个向量仅能代表一个单词的含义, 而不涉及其周边环境的信息,但我们的主要目标是让这些向量通过网络传递,使每一个向量都能获得比单个词更丰富、更具体的含义。
Which is A token has the capacity to absorb its context-meaning
Context
这个网络每次只能处理一定数量的向量这就是所谓的上下文大小。
意味着数据在 Transformer 网络中流动时, 总是看起来像一串 2048 列的数组。

:smile:
In the final
End should look like this:

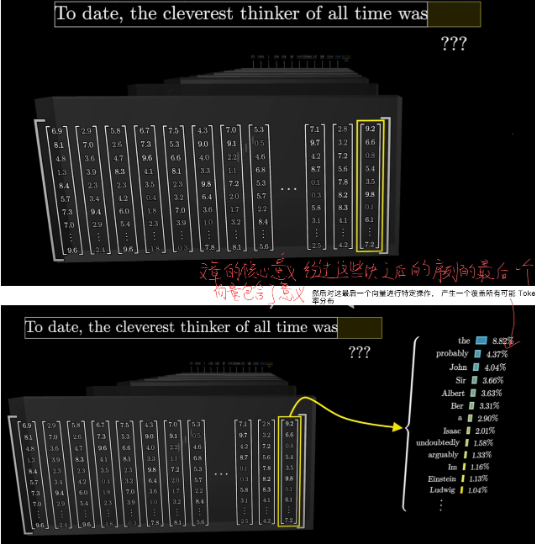
Its final goal is to have a distribution of probability Because Transformer is a prediction model in the end.
So We have our processed vectors-composed Sequence(上下文),We just need its last column
使用另一个矩阵 Unembedding matrix, 将上下文中的最后一个向量映射到 to a list of 50,000 values, one for each token in the vocabulary.词汇表中的每个 token 都对应一个值,接着,通过一个函数,把这些值转换成概率分布。这个函数叫 softmax,仅仅基于最后一个嵌入来做出预测似乎有些奇怪, 毕竟在最后一层中还有成千上万的其他向量,这是因为在训练过程中, 如果我们利用最终层的每一个向量来预测其后可能出现的内容,被证明是更高效的方法。
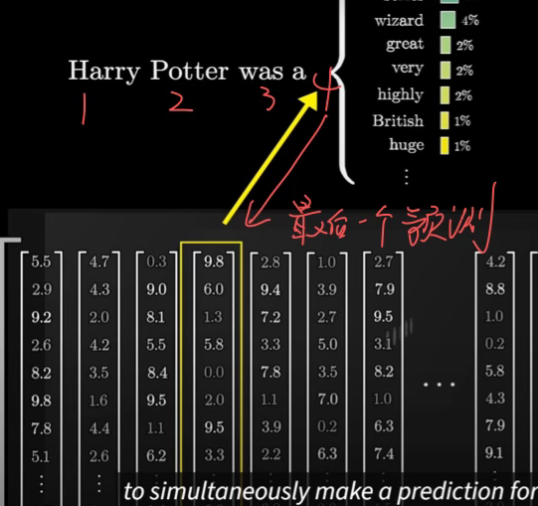
怎么确定 50,000 values
关于参数总数的统计, 这个 unembedding 矩阵为词汇表中的每个单词都分配了一行,每一行包含与嵌入维度相同数量的元素。这与嵌入(embedding)矩阵非常相似,只不过是把顺序倒过来了, 因此它为网络增加了另外 6.17 亿个参数。
Softmax
我们的最后计算都是矩阵和 vector 的计算,最后得不到一个概率分布,所以需要一个归一化函数 输入是 logits 输出是 Probabilities

现在引入一个人为的温度
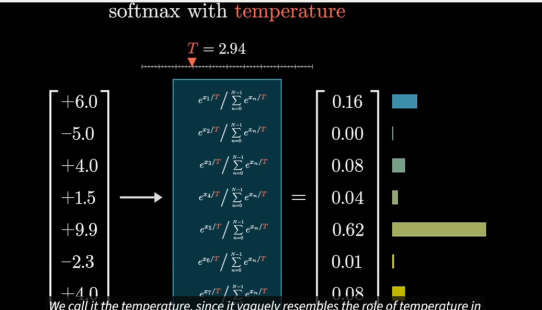
它的效果是,当 t 值较大时,会使较小的数值获得更多的权重, 使得分布稍微均匀一些。而如果 t 值较小则较大的数值则会更加明显地占据主导,极端情况下,0 温度为 0 意味着它总是选择最可预测的词 那么所有的权重都会集中在最大的值上。
温度为 0 意味着它总是选择最可预测的词,而你所得到的结果就变成了一个陈词滥调的金发姑娘故事。较高的温度给它提供了选择不太可能出现的词的机会,但这也伴随着风险。但很快就变得毫无意义。API 实际上并不允许你选择大于 2 的温度。这个限制并没有数学上的根据, 只是一个人为的限制,我猜目的是为了防止他们的工具产生太过荒诞的结果。